Relacionado: Ver SDLC para el ciclo completo. OWASP Top 10 para vulnerabilidades comunes. Buffer Overflow como ejemplo de falta de validación. OAuth 2.0 para autenticación segura.
Excelente contenido. A continuación te presento una versión revisada, mejor redactada, estructurada y enriquecida, para que quede claro y formal, ideal para un informe o guía técnica sobre validación de datos de entrada y seguridad en el desarrollo seguro:
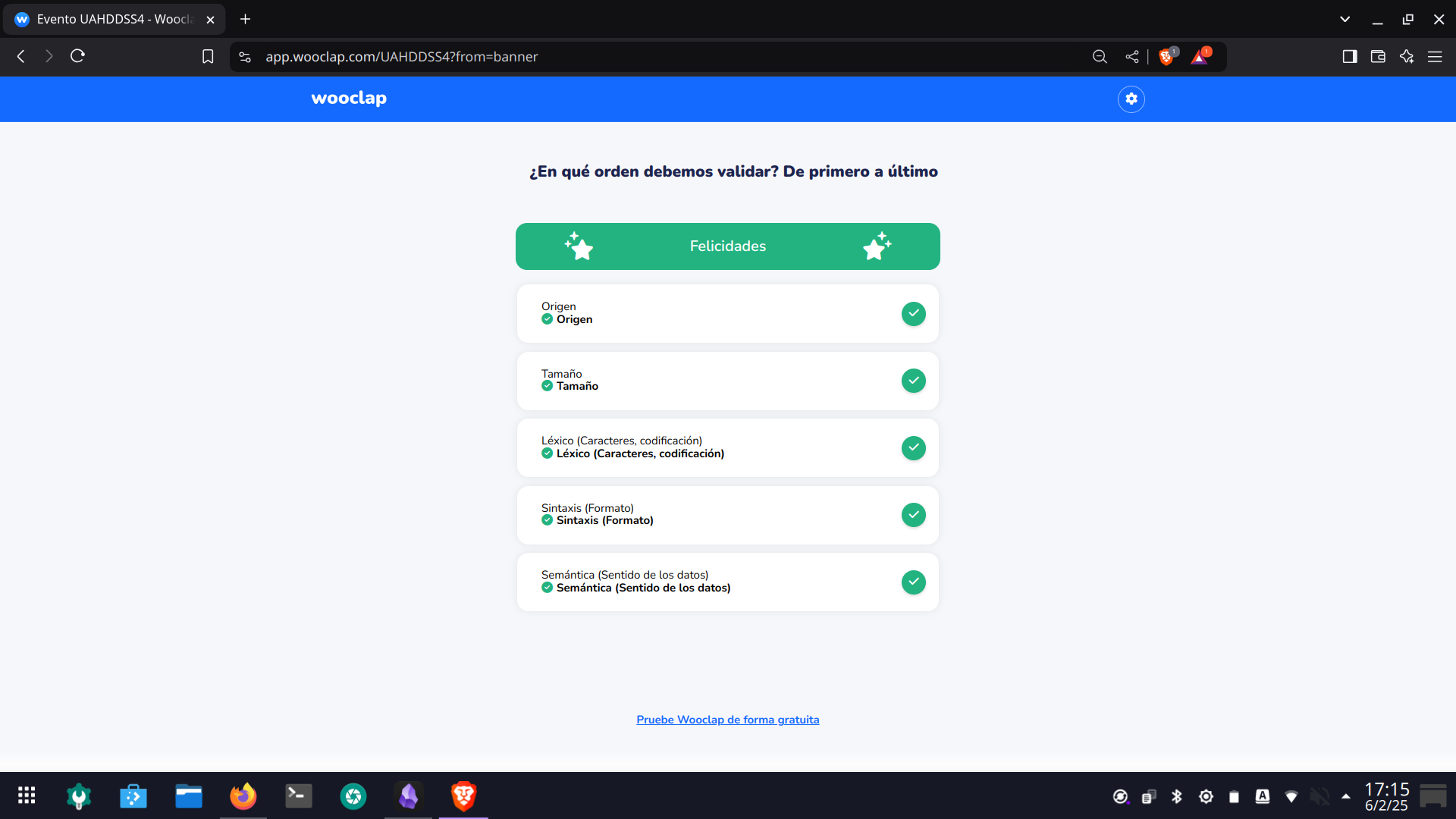
Orden de validación de datos de entrada
El proceso de validación de datos de entrada es un componente esencial del desarrollo seguro. Su correcto diseño permite proteger las aplicaciones frente a múltiples amenazas, como inyecciones, corrupción de datos o fallos lógicos.
El orden recomendado para validar los datos contempla diferentes aspectos clave:
1️⃣ Origen de los datos
Primero debe verificarse de dónde provienen los datos. Si los datos atraviesan una frontera de confianza (por ejemplo, si llegan desde un cliente externo o un sistema no confiable), será necesario aplicar validaciones más estrictas y controles adicionales.
Esto se basa en el principio de no confiar en datos externos, independientemente de su apariencia.
2️⃣ Tamaño
Comprobar que los datos no superan los límites establecidos:
-
Longitud (por ejemplo, número máximo de caracteres permitidos en un campo).
-
Valor numérico (por ejemplo, que un número esté dentro de un rango válido).
Esto ayuda a prevenir ataques como desbordamientos de buffer o inyecciones masivas de datos.
3️⃣ Léxico
Verificar que los caracteres que componen el dato sean aceptables en el contexto previsto.
Ejemplos:
-
Permitir solo dígitos en un campo de teléfono.
-
Permitir solo letras en un campo de nombre.
4️⃣ Sintaxis
Revisar la estructura general del dato para asegurar que sigue el formato esperado.
Ejemplos:
-
Comprobar que una dirección de correo electrónico está correctamente formada.
-
Validar que un código postal sigue el patrón establecido.
5️⃣ Semántica
Por último, comprobar que el valor del dato tiene sentido en su contexto de uso.
Ejemplos:
-
Que una fecha esté dentro de un rango lógico (mayor que 1900 y menor o igual al año actual).
-
Que un importe monetario no sea negativo si no corresponde.
Conceptos clave adicionales en desarrollo seguro
FSSC (Fail-Safe State Control)
FSSC está relacionado con la gestión segura de la memoria, asegurando que las operaciones sobre ella se realicen de forma controlada para evitar problemas como:
-
Corrupción de datos
-
Fugas de memoria
-
Desbordamientos
Una gestión adecuada de la memoria es fundamental para proteger la integridad de los sistemas y prevenir vulnerabilidades críticas, como las explotadas por ataques de tipo buffer overflow.
DDSS (Definición y Almacenamiento Seguro de Datos)
DDSS hace referencia a los mecanismos y servicios que permiten definir y almacenar datos de forma segura, asegurando que la información se gestione bajo los principios de:
-
Confidencialidad: protección frente a accesos no autorizados.
-
Integridad: protección frente a modificaciones no autorizadas o accidentales.
-
Disponibilidad: garantizar que los datos estén accesibles cuando se necesiten.
Esto incluye el uso de bases de datos protegidas, controles de acceso robustos, cifrado en reposo y en tránsito, así como políticas para la correcta eliminación segura de datos cuando ya no sean necesarios.
Validación de datos y seguridad en tipos y primitivas de dominio
Validación de datos en la frontera de confianza
Es fundamental aplicar una validación rigurosa de los datos que cruzan la frontera de confianza. Todo dato que proviene de un contexto externo —por ejemplo, entradas de usuarios, peticiones web o datos de sistemas terceros— debe ser validado antes de ser procesado, ya que puede ser la fuente de ataques como inyecciones de código, manipulación maliciosa o corrupción de datos.
Validar adecuadamente en este punto protege la aplicación contra amenazas comunes, como SQL injection, command injection o desbordamientos de buffer, y constituye una práctica esencial dentro de los principios de desarrollo seguro.
Seguridad de tipos y tipado en los lenguajes de programación
El manejo de tipos y su relación con la seguridad es clave para evitar errores sutiles que puedan derivar en vulnerabilidades. Existen diferentes modelos de tipado:
Tipado estático
En lenguajes de tipado estático, el tipo de una variable está definido en tiempo de compilación y no puede cambiar posteriormente.
-
La variable se puede entender como una “caja” que contiene un valor cuyo tipo es fijo e inmutable una vez declarado.
-
Esto permite a los compiladores detectar incongruencias de tipos antes de ejecutar el programa, reduciendo errores y mejorando la seguridad.
Tipado dinámico
En lenguajes de tipado dinámico, la “caja” contiene tanto el valor como su tipo, y el tipo puede cambiar en tiempo de ejecución.
- Esto otorga gran flexibilidad, pero también requiere mayor precaución y validaciones adicionales en tiempo de ejecución, ya que los errores de tipo pueden manifestarse solo al ejecutar el código.
Tipado débil
En lenguajes con tipado débil, las conversiones entre tipos pueden ocurrir de forma implícita y poco estricta, como convertir automáticamente un char a int sin advertencia ni control explícito.
- Esto facilita errores sutiles y puede generar problemas de seguridad difíciles de detectar y depurar.
Duck typing (ejemplo en Python)
Python adopta un enfoque basado en duck typing, donde lo importante no es el tipo exacto del objeto, sino que el objeto implemente el comportamiento o interfaz esperada:
“Si camina como un pato y grazna como un pato, es un pato”.
En Python, no se comprueba el tipo concreto sino si el objeto admite las operaciones necesarias, lo que incrementa la flexibilidad pero obliga a ser especialmente cuidadosos en las validaciones para evitar fallos en tiempo de ejecución.
Primitivas de dominio
Una primitiva de dominio es una definición específica que encapsula un concepto del dominio de negocio, permitiendo representar valores válidos de forma segura y consistente, evitando estados ilegales.
Se suele implementar como clase o estructura que incluye reglas de validación integradas, de forma que:
-
Siempre que se cree una instancia, los valores estarán automáticamente validados.
-
Se evita la propagación de validaciones dispersas por el código, centralizando la lógica y reforzando la integridad.
Ejemplo:
CantidadLibro: representa el número de libros en un inventario.
Restricciones:
- Tipo: entero no negativo.
- Rango: > 0 y ≤ 50.Con esta primitiva de dominio se garantiza que nunca podrá existir una cantidad negativa, cero o superior al límite máximo permitido, eliminando toda clase de errores relacionados con estados inconsistentes o inválidos.
Si quieres, puedo añadir:
-
Un diagrama comparativo de los modelos de tipado (estático, dinámico, débil).
-
Ejemplos de implementación de primitivas de dominio en Python o en otro lenguaje.
Dímelo y lo preparamos.
Validación csv
Hemos seguido los pasos siguientes:
1º Obtenemos el csv.
2 Comprobamos su origen comprobando la firma del criptográfica del profesor para comprobar el origen y la integridad del mensaje y si corresponde al profesor.
3º Comprobamos el tamaño del mensaje si es de cero bytes no será admitido y si es más de 1gb tampoco será admitido.
4º Validamos el encondig en el caso de que estamos en España el Enconding usado será utf-8 ya que permite el uso de ñ y tildes.
5º Establecemos como formato que los valores de los campos van separado por ; y cada fila se representa con un nuevo salto de linea.
6º Validamos que el número de filas se corresponde con el numero de alumnos ,más la fila de la cabecera.
7º Comprobamos que haya campo cabecera.
8º Para cada fila, sin contar la cabecera, hacemos un split por el ; para conseguir cada campo.
9º Comprobamos que cada campo tiene su formato correspondido por ejemplo nombre es un texto, nota es un float.
10 º Para cada campo recogido por cada fila comprobamos su cardinalidad es decir si es opcional o obligatorio, en caso de falta un campo obligatorio dará error.
11º Cada campo se evaluará de forma semántica utilizando expresiones regulares.
- Nombre: [ A-Z ][a-z]+\s+[ A-Za-z ]+ - Apellidos1: ([ A-Za-z -])
- Apellido2: ([ A-Za-z -])? - Nota, (En el caso de ser varias se aplicaría el mismo patrón): (10|NP|\d(.\d\d)?))
Actividad definir primitivas de dominio para cada elemento
DNI (Documento Nacional de Identidad)
- Definición: Es un identificador que de los ciudadanos de España.
- Composición:
- En España, son 8 dígitos seguidos de una letra.
- Almacenamiento: Se puede guardar en un int ya que tiene 32 bit es decir cabe hasta 2 elevado a 32, permitiendo poder utilizar 10 dígitos suficiente para guardar los 8 dígitos, la letra no la guardamos ya que se puede obtener a partir de dígitos.
- Validación:
- Verificar que tenga 8 números seguidos de una letra.
- Calcular la letra de control con el módulo 23 del número y compararla con la esperada.
Dirección de E-mail
- Definición: Es un identificador de correo electrónico .
- Composición:
- Formato general:
usuario@dominio.ext - El usuario puede contener letras, números, puntos y guiones bajos.
- El dominio debe seguir un formato DNS válido.
- Formato general:
- Almacenamiento: Se guarda como una cadena de texto .
- Validación:
- Podemos usar la siguiente expresión regular para validar el correo (
^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$). - Verificar si el dominio del correo existe.
- Podemos usar la siguiente expresión regular para validar el correo (
Dirección IP (IPv4 e IPv6)
-
Definición: Identificador del protocolo IP.
-
Composición:
- IPv4: 4 grupos de números entre 0 y 255 (ej.
192.168.1.1). - IPv6: 8 grupos de valores hexadecimales de 16 bits (ej.
2001:0db8:85a3::8a2e:0370:7334).
- IPv4: 4 grupos de números entre 0 y 255 (ej.
-
Almacenamiento:
- Se pueden guardar tanto como una cadena de texto para que su representación sea, más sencillo, pero la mejor forma sería o bien guardarla en hexadecimal, o bien si usamos postgerSQL podemos usar INET. Luego para mostrarla podemos hacer un casteo para convertir ese campo a otro como texto para poder mostrarse mejor.
-
Validación:
- Expresiones regulares para validar el formato.
- Conversión a binario para verificar rangos válidos.
Nombre
-
Definición: Identificador de una persona.
-
Composición:
- Cadena Alfabética que permite espacios en el caso de que sea compuesto.
-
Almacenamiento: Se guarda en formato texto con codificación utf-8 al estar en España, si se guardasen nombres asiáticos, deberíamos usar utf-16
-
Validación:
- Evitar caracteres especiales no permitidos (expresión regular
[a-zA-ZÀ-ÿ'-\s]+).
- Evitar caracteres especiales no permitidos (expresión regular
Contraseña de una sola lectura (OTP, One-Time Password)
- Definición: Código de seguridad válido para un solo uso.
- Composición:
- Cadena alfanumérica.
- Almacenamiento:
- Se almacena en formato hash con un duración predeterminada.
- Validación:
- Comparación con el hash almacenado.
URL
- Definición: Dirección única que apunta a un recurso en la web.
- Composición:
- Formato general:
protocolo://dominio/ruta?parametros - Debe incluir un esquema (
http,https,ftp).
- Formato general:
- Almacenamiento: No sé almacena, el límite es de 2083 caracteres.
- Validación:
- Expresión regular para validar sintaxis (
^(https?|ftp):\/\/[^\s/$.?#].[^\s]*$). - Intento de acceso para verificar disponibilidad.
- Expresión regular para validar sintaxis (